Una guía práctica para garantizar calidad en tus modelos de IA
Hace poco, trabajando con Large Language Models (LLMs) en proyectos reales, confirmé algo que ya sospechaba: no importa lo avanzado que sea el modelo, si no tienes un sistema de QA sólido detrás, el riesgo de errores graves es altísimo.
Al trabajar con este tipo de implementaciones, me he dado cuenta de que las estrategias de pruebas de software son ligeramente similares a las que usamos en proyectos tradicionales (planificación, diseño, ejecución), pero con un enfoque muy diferente: aquí debemos eval uar la visión global del modelo generado.
Muchas veces podemos enfocarnos solo en que el modelo “responda”, “hable bonito” o genere respuestas rápidas… pero olvidamos que cada palabra que entrega tiene un impacto en la confianza de los usuarios, en la reputación de la marca y en los objetivos de negocio.
Por eso quiero compartir contigo mi experiencia en este proceso, lo que he implementado para asegurar la calidad en LLMs y cómo puedes crear un roadmap claro para aplicarlo en tu empresa o tus proyectos.
1. Define el alcance de la medición
Algo que aprendí es que calidad no significa solo que la respuesta esté correcta. Hay varios pilares que debemos medir:
Integridad factual: que el modelo genere la información correcta dentro de un contexto dado y que no “alucine”.
Relevancia: que realmente responda a lo que el usuario preguntó.
Tono y voz de marca: que lo que genera esté alineado con la identidad de la empresa.
Sesgos: que el contenido sea justo, sin prejuicios ni lenguaje discriminatorio.
He podido comprobar que cuando uno de estos pilares falla, el impacto en el negocio es inmediato: pérdida de confianza, riesgos legales o usuarios que dejan de interactuar con el sistema.
2. Diseña un proceso por etapas
En mi experiencia, el error más común en QA para LLMs es querer revisar todo con lupa desde el inicio, y eso no escala.
Lo que mejor me ha funcionado es un proceso de validación por etapas:
Revisiones automáticas rápidas para todo (reglas generales, legibilidad, detección de incertidumbre).
Análisis más profundos solo en los casos sospechosos o en una muestra (métricas semánticas).
Revisión humana enfocada en lo crítico o ambiguo.
Esto permite tener cobertura total sin sobrecargar el presupuesto ni al personal de QA.
3. Verifica las métricas que realmente importan
En los proyectos es importante definir si tu evaluación requiere métricas léxicas, semánticas o ambas.
Las léxicas (como ROUGE o BLEU) evalúan el solapamiento de palabras.
Las semánticas (como BERTScore o las métricas de RAGAS) analizan el significado.
Debes comparar cómo se comporta el modelo frente a la fuente de información y priorizar las métricas que más aporten según tu presupuesto y el tiempo disponible para la implementación.
4. Evalúa lo cualitativo
Aquí entra el lado más estratégico del aseguramiento de calidad: no solo se trata de medir datos, también debemos evaluar si el contenido “se siente” correcto.
Voz de marca: siempre recomiendo partir de un Brand Voice Doc con tono, palabras clave y ejemplos.
Tono y sentimiento: uso clasificadores que detecten si el texto es formal, empático, positivo, neutro o negativo.
Legibilidad: se pueden usar librerías o APIs para verificar que el texto generado sea comprensible para el público objetivo.
En los modelos generativos, cuando descuidamos estos detalles, el modelo puede ser técnicamente correcto… pero generar rechazo.
5. Usa el enfoque “LLM-as-a-Judge”
Algo que me ha funcionado es usar un LLM para evaluar las respuestas de otro. Pero ojo: esto requiere prompts de evaluación claros y calibrar continuamente el modelo evaluador.
Puedes hacerlo de tres formas:
Dándole un único output y pidiéndole una calificación.
Comparando dos respuestas y eligiendo la mejor.
Usando una respuesta de referencia para medir fidelidad (mi enfoque preferido).
Este método permite medir fidelidad, relevancia y consistencia. Eso sí, también debes considerar el costo de la API de consulta del modelo juez.
6. Utiliza frameworks y librerías
Según tu presupuesto, puedes usar herramientas open source como OpenAI Evals, DeepEval o RAGAS, o plataformas comerciales como Galileo AI, Arize AI o Vertex AI Evaluation.
En mi caso, inicié con open source, implementando un script en Python con la librería RAGAS, enfocado en 3 métricas semánticas clave:
Faithfulness (Fidelidad): mide si la respuesta es fiel al contexto aunque use palabras o estructuras distintas.
Answer Relevancy (Relevancia): evalúa si la respuesta responde realmente la intención de la pregunta.
Semantic Similarity (Similitud Semántica): compara la respuesta generada con la respuesta ideal (ground truth).
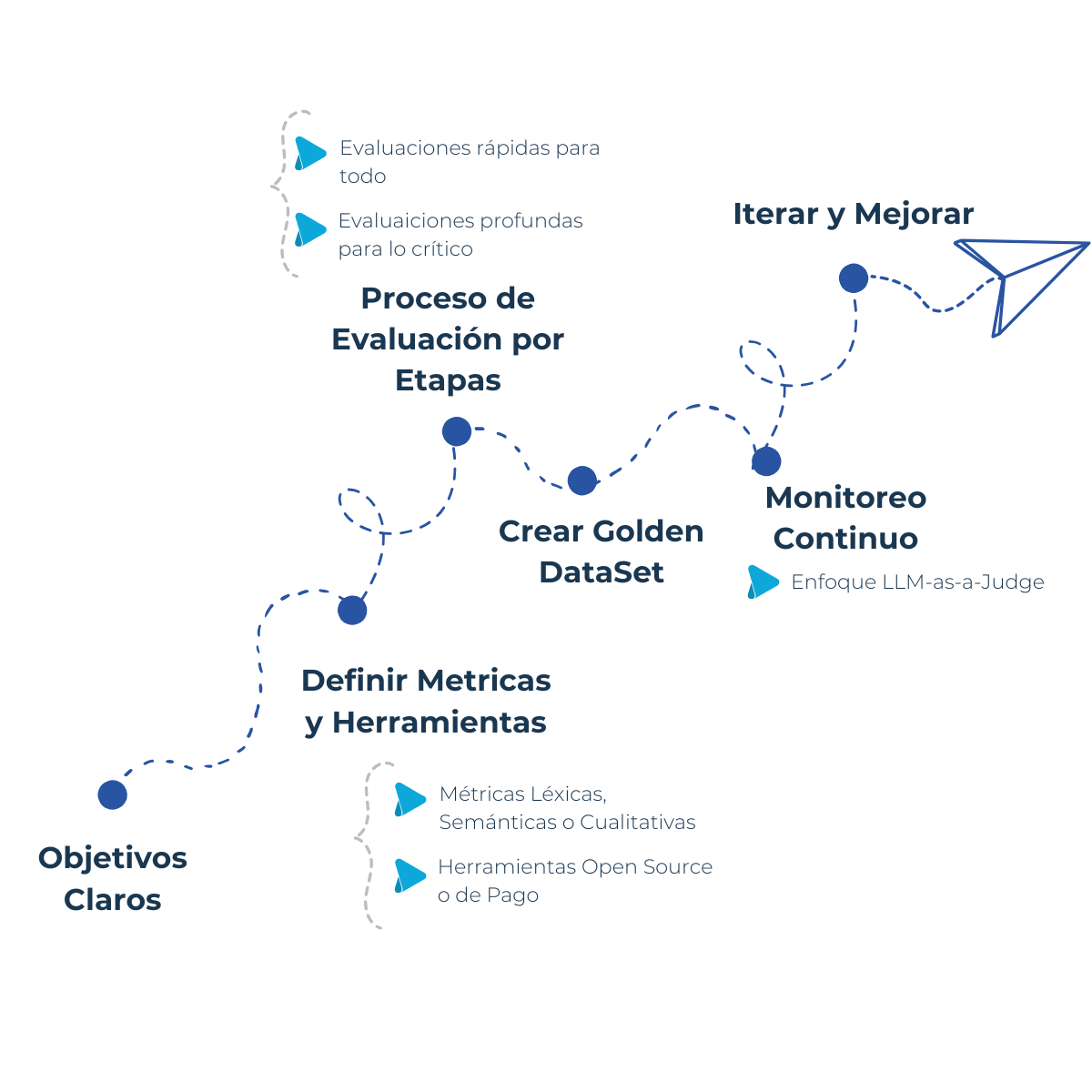
Roadmap recomendado para implementar QA en LLMs
Define objetivos claros: ¿Qué significa “calidad” en tu caso?
Selecciona métricas y herramientas: mezcla lo léxico, semántico y cualitativo según presupuesto y alcance.
Diseña un proceso de evaluación por etapas: validaciones rápidas para todo + evaluaciones profundas para lo crítico.
Crea un Golden Dataset: casos de prueba con respuestas ideales (si es necesario).
Implementa monitoreo continuo: crea alertas y usa el enfoque LLM-as-a-Judge.
Itera y mejora: recalibra métricas y prompts según los resultados.